- Künstliche Intelligenz
- Artificial Intelligence
- 人工知能
Fragen
- Lohnt es sich, ein System unter ethischer Perspektive zu evaluieren? -> Algoskop
- Ist es KI? -> KIometer
KIometer
- lernt es?
- ist es komplex?
- benutzt es viele Daten?
Algoskop
»Algorithmen«. Diese Fokussierung auf ethisch relevante algorithmische Entscheidungssysteme nenne ich das Algoskop. (KZ-AKT 24)
Aus der obigen Zusammenfassung ergibt sich, dass nur eine relativ kleine Klasse von Softwaresystemen unter einer ethischen Perspektive betrachtet werden sollte. Dies sind primär solche, die aus Daten lernen, wie sich Menschen in der Vergangenheit verhalten haben, um daraus Schlüsse über das mögliche zukünftige Verhalten von anderen Menschen zu ziehen und solche, die über den Zugang zu gesellschaftlichen Ressourcen entscheiden. (KZ-AKT 282-3)
- Software
- Algoritmische Entscheidungssysteme
- mit lernender Komponente
- die über Menschen entscheidet
- AES sind unkritisch, wenn über Dinge entschieden werden soll, die keinen direkten Bezug zu Menschen oder zur Gesellschaft haben.
- AES sind kritisch:
- wenn es um Menschen geht
- wenn es um die Teilhaber an der Gesellschaft geht
- wenn es um Zugang zur wichtigen Ressourcen geht
Ergo: Nur eine relativ kleine Klasse von Softwaresystemen braucht unter ethischer Perspektive betrachtet werden.
Diese sind primär solche, die aus Daten lernen, wie sich Menschen in der Vergangenheit verhalten haben, um daraus Schlüsse über das mögliche zukünftige Verhalten von anderen Menschen zu ziehen und solche, die über den Zugang zu gesellschaftlichen Ressourcen entscheiden. (SZ-GT, Pos3631)
OMA-Prinzip
Operationalisierung
- operationale Definition eines Konzeptes
- Messbarmachung
- der modellierten Objekte
- das, was eine gute Entscheidung ist
Operationale Definition:
»An operational definition is a procedure agreed upon for translation of a concept into measurement of some kind.« Zitiert aus: W. E. Deming: The new economics – for Industry, Government, Education, MIT Press Ltd., Cambridge/Massachusetts (2000), S. 105
Modell der Welt
Die Modellierung eines Problems ist auch immer schon selbst ein Problem. -> Explikation
Unterschied zwischen
- Land und Landkarte
- Situation und Konstellation
- echte Situation und künstliche Repräsentation
Wenn die Modellierung nicht mit dem Algorithmus abgestimmt ist, rechnet dieser zwar etwas aus, dies lässt sich aber nicht sinnvoll interpretieren. (KZ-AKT 80)
Das Problem ist, dass wir Menschen in den meisten Situationen so viele Regeln intuitiv berücksichtigen, dass es unmöglich erscheint, all dieses Wissen strukturiert abzulegen. (KZ-AKT 127)
Es stellte sich aber heraus, dass es sehr mühsam ist, all das implizite Wissen abzulegen. (KZ-AKT 127)
Das Modell der Welt muss abgeglichen werden mit den erfolgten Operationalisierungen und dem Algorithmus. (KZ-AKT 172)
Ich habe zuerst betont, dass die wichtigste Gestaltungsleistung bei klassischen Fragestellungen die Modellierung der Alltagssituation darstellt, also ihre Vereinfachung, sodass einer der vielen klassischen Algorithmen ganz ohne maschinelles Lernen eine optimale Lösung berechnen kann. (KZ-AKT 201)
Algorithmus
- Input: Daten
- Nutzung vorhandener Algorithmen
- Output: Daten -> Bedetungsgebung -> Interpretation
Denn nicht alle Algorithmen lernen von Daten. Die allermeisten sind »klassische« Algorithmen und somit auch einigermaßen beherrschbar. Und die Algorithmen, die aus Daten »lernen«, sind selbst statisch – sie verändern sich nicht. (KZ-AKT 129)
Lange Kette der Verantwortlichkeiten
...
Kein Algorithmen-TÜV sondern systemischer Blick
Ganzheitliche Betrachtung des soziotechnischen Gesamtsystems
Im Nachhinein ist mir aber auch bewusst geworden, dass das systemische Denken, das ich aus der Biochemie kannte, in der Informatik weitgehend fehlt – etwas, das wir jetzt gut gebrauchen könnten, wo Algorithmen die Gesellschaft immer stärker beeinflussen! (KZ-AKT 64)
Ich habe Ihnen anhand einiger Beispiele aber gezeigt, dass der »Algorithmen-TÜV« nicht der richtige Ort ist, wenn es um die Frage der sinnvollen Anwendung eines algorithmischen Entscheidungssystems in einem komplexen sozialen Prozess geht. Der Grund dafür liegt darin, dass erst der soziale Kontext die möglichen Risiken festlegt und damit auch das Qualitätsmaß bestimmt. Um das Schadenspotenzial des sozio-technischen Gesamtsystems zu analysieren, bedarf es Personen, die die dafür notwendige Ausbildung haben. (KZ-AKT 283-4)
Big Data
- Volume (Masse)
- Velocity (Geschwindigkeit)
- Variety (Vielfältigkeit)
Big Data wird dann genutzt, wenn vorhanden:
- Mehrwert (Value)
- Validität (Validity)
Maschinelles Lernen
Der Prozess ist weit weniger objektiv und selbstgesteuert, als Sie es vermuten würden. (KZ-AKT, 23)
Es ist aber auch klar geworden, dass künstliche Intelligenz mit einer lernenden Komponente immer nur Plan B ist. (KZ-AKT 193)
Maschinelles Lernen ist also nur Plan B – leider gibt es aber oft keinen Plan A, denn viele der anstehenden Probleme können mit klassischen Algorithmen nicht gelöst werden. (KZ-AKT 204)
KI mit einer lernenden Komponente ist nur Plan B – wenn ein Expertensystem gebaut werden kann, sollte man das machen. (KZ-AKT 230)
Prinzip:
- Input: Regel
- Output: Feedback gegenüber Grundwahrheit -> stärkt oder schwächt die Regel
Maschinelles Lernen kann also im Wesentlichen dort erfolgreich sein, wo die folgenden Bedingungen erfüllt sind:
- Es gibt eine ausreichend große und gute Trainingsdatenmenge (Input).
- Es gibt eine sehr gut messbare Grundwahrheit, also das, was vorherzusagen ist (Output).
- Es gibt kausale Zusammenhänge zwischen dem Input und dem vorherzusagenden Output.
Algorithmen des maschinellen Lernens sind uns in diesem Fall klar überlegen, da sie:
- nahezu beliebig große Datenmengen nach Korrelationen durchsuchen können.
- nach sehr vielen verschiedenen Arten von Korrelation suchen können.
- auch schwache Korrelationen noch gewinnbringend in die statistischen Modelle einfließen lassen können.
...
Die Ergebnisse maschinellen Lernens werden dann für uns glaubhaft, wenn zusätzlich das Folgende gilt:
- Der kausale Zusammenhang zwischen dem Input und dem vorherzusagenden Output ist so weit bekannt, dass es eine klar definierbare Menge an Inputdaten gibt, auf die sich alle beteiligten Akteur:innen leicht einigen konnten.
- Es gibt möglichst viel Feedback für beide Fehlertypen (falsch-positiv und falsch-negative Entscheidungen). Damit kann die Qualität fortlaufend gemessen und das statistische Modell dynamisch nachgebessert werden.
- Es gibt ein klar definierbares Qualitätsmaß, auf das sich alle beteiligten Akteur:innen leicht einigen konnten.
(KZ-AKT 196)
Maschinelles Lernen versucht, Zusammenhänge zwischen Inputdaten und einem beobachteten Ergebnis (Output) zu identifizieren. Es werden Algorithmen verwendet, die Korrelationen, die sie in einem Trainingsdatensatz gefunden haben, in Form von Entscheidungsregeln in einer von mehreren möglichen Strukturen abspeichern (zum Beispiel Entscheidungsbäume, mathematische Formeln, Support Vector Machines, neuronale Netzwerke). Dabei gibt es viele Hyperparameter (Knöpfe, Schieber, Regler), die einzustellen sind. Zudem kann durch das Verändern der Eingangsdaten (feature engineering) die Qualität der Vorhersage verändert werden. (KZ-AKT 202)
Durchführung 1. Algo: Maschinelle Lernalgorithmus
- Algorithmen des maschinelles Lernens
- Input: viele vorhandene Daten mit bekanntem Ergebnis
- Ziel: Der Computer soll anhand von konkreten Beispielen und vorhandenen Grundwahrheiten möglichst generalisierte Regeln lernen.
Algorithmen des maschinellen Lernens sind sehr datenhungrig. (KZ-AKT 172)
Das ist maschinelles Lernen: Automatisiertes Lernen an Beispielen, in denen Entscheidungsregeln gesucht und in einem statistischen Modell abgelegt werden. (KZ-AKT 132)
Denn auch der erste Algorithmus hat nichts Magisches, er ist auch nicht »objektiv« im allgemeinen Sinne. (KZ-AKT 133)
Ich erkläre skizzenhaft, wie Algorithmen oder Heuristiken diese Regeln jeweils aus den Daten lernen und wie sie dann in einem statistischen Modell gespeichert werden:
- Der Baum der Erkenntnis: Entscheidungsbäume
- Der Holzspießtest aka Support Vector Machines
- Und – sehr skizzenhaft – neuronale Netzwerke (KZ-AKT 134)
Grundsätzlich versucht man beim maschinellen Lernen, nicht zu viel in das vorliegende Datenset hineinzuinterpretieren – falls das doch passiert, nennen wir das »Overfitting«. (KZ-AKT 140)
Die Methoden des maschinellen Lernens sind Methoden der Korrelationssuche. Das heißt, sie suchen nach Eigenschaften, die mit der vorherzusagenden Eigenschaft sehr oft gemeinsamen auftreten (und weniger oft auftreten, wenn ein Datenpunkt die vorherzusagende Eigenschaft nicht hat). (KZ-AKT 194)
Ergebnis: trainiertes statistisches Modell
Im Gegensatz zum klassischen Algorithmendesign, wo die Modellbildung (Definition des mathematischen Problems) vor dem Entwurf und Einsatz des Algorithmus liegt, baut jetzt der Algorithmus aus den Daten das Modell der Welt. (KZ-AKT 44)
Die vom Computer gefundenen Muster werden in Form von Entscheidungsregeln oder Formeln in einer geeigneten Struktur abgespeichert. Diese Struktur nennen wir auch das statistische Modell. (KZ-AKT 132)
... viele der Methoden des maschinellen Lernens sind aber eben solche Heuristiken. (KZ-AKT 80)
Von den Daten her gesehen ist es genau das, was maschinelles Lernen leisten können soll: Versteckte Entscheidungsregeln offenlegen, auch wenn diese nicht zu 100 Prozent das Handeln leiten und weitere Eigenschaften eine Rolle spielen könnten. (KZ-AKT 145-6)
Die meisten Algorithmen des maschinellen Lernens sind nur Heuristiken, also Handlungsanweisungen, die versuchen, überhaupt eine Lösung zu finden, aber nicht garantieren können, dass es die optimale ist. (KZ-AKT 194)
Entscheidungsbäume können relativ schnell aus Daten gelernt werden. Die Algorithmen dahinter sind im Wesentlichen simpel, aber nicht trivial, da so viele Entscheidungen getroffen werden müssen. Viele dieser Entscheidungen führen zu Handlungsanweisungen, die technisch gesehen keine Algorithmen mehr sind, sondern nur Heuristiken. Das ist bei den allermeisten Methoden des maschinellen Lernens der Fall. (KZ-AKT 147)
Wenn es aber nicht möglich ist, eine hundertprozentig gültige Regel zu finden, müssen die verschiedenen Fehler einer Entscheidung gegeneinander abgewogen werden. (KZ-AKT 158)
Offensichtlich kommt es bei maschinellem Lernen aber nie dazu, dass die von der Maschine festgestellten Hypothesen auf ihre Kausalität überprüft werden. (KZ-AKT 194)
Wurde die Struktur aufgebaut, sprechen wir vom trainierten statistischen Modell. Neue Daten werden dann mithilfe eines zweiten, sehr einfachen Algorithmus durch das statistische Modell geleitet – es kommt als Entscheidung eine einzige Zahl heraus. Diese kann eine Klassifikation oder eine Risikobewertung repräsentieren. (KZ-AKT 202)
Es ist für mich als Naturwissenschaftlerin ebenfalls nur wenig nachvollziehbar, warum die von den Maschinen gefundenen Korrelationen nicht in klassischen Experimenten auf ihre Stichhaltigkeit überprüft werden, bevor sie verwendet werden dürfen. ... Aber am Ende sollten nur noch Variablen Eingang in das statistische Modell finden, bei denen ein kausaler Zusammenhang begründbar ist. ... Und wenn man die Kausalketten kennt, dann braucht man vermutlich auch keine gelernten statistischen Modelle mehr, sondern kann die Erkenntnisse in für Menschen lesbarer Form als Entscheidungsregeln speichern. (KZ-AKT 264)
- Modell der Welt
- gelernte Regeln, Heuristiken
- in einem statistischen Modell abgelegte Entscheidungsregeln
Durchführung 2. Algo: Entscheidungsalgorithmus
Und der zweite Algorithmus, der die gefundenen Regeln abläuft und die eigentliche Entscheidung trifft, enthält nur einfache Multiplikationen, Additionen und »Wenn-dann«-Entscheidungen. Er bedarf weder einer Regulierung noch einer Überprüfung durch einen TÜV. (KZ-AKT 133-134)
Der eigentliche Qualitätstest besteht also darin, wie gut die gefundenen Regeln auf den Teil der Daten anwendbar sind, die der Algorithmus nicht zur Verfügung hatte. (KZ-AKT 143)
Korrelation und Kausalität
Als Kausalkette bezeichne ich dabei eine Aneinanderreihung von Fakten, die erklären, wieso es zu einer bestimmten Beobachtung kommt. Das maschinelle Lernen verspricht nun genau dies: dass die reine Korrelation von Daten mit beobachtetem Verhalten ausreichend sein könnte, um Entscheidungen über neue Daten zu fällen. (KZ-AKT, 38)
Und daher gibt es wissenschaftstheoretisch auch kein Entrinnen: Eine reine Hypothese, die nicht getestet wurde, gilt nicht als Fakt. Erst mehrere überprüfte Hypothesen, die in Experimenten nicht widerlegt werden konnten, werden in einer Theorie zusammengefasst – und erst dann, wenn diese Theorie zu Vorhersagen führt, die sich in kontrollierten und wiederholbaren Experimenten oder in der freien Natur als korrekt erweisen und dies mehrfach, beginnen wir, von einem Fakt zu sprechen. (KZ-AKT, 40)
Qualitäts- und Fairnessmaße
Menschen müssen definieren, was eine gute Entscheidung ausmacht, damit das Resultat des maschinellen Lernens überhaupt gute Entscheidungen produzieren kann. Die Qualitätsmaße – und daneben auch etwas, das wir »Fairnessmaße« nennen – bestimmen maßgeblich, was der Computer lernt. Und glücklicherweise bedarf es wenig technischen Grundwissens, um hier mitreden zu können! (KZ-AKT 156)
Es ist einfach unwahrscheinlich, dass das Qualitätsmaß, mit dem das System trainiert wurde, der Situation in Ihrer Firma entspricht. (KZ-AKT 163)
Das Beispiel zeigt, dass die Wahl des Qualitätsmaßes immer auch eine moralische Abwägung enthält, nämlich die Frage, welche Fehlentscheidung schwerer wiegt. (KZ-AKT 165)
Wenn das Qualitätsmaß nicht zur Situation passt (Sommerreifen sind kein Garant für Fahrsicherheit), kann es so hoch sein, wie es will. (KZ-AKT 172)
Die Qualität wird anhand eines Qualitätsmaßes auf einem Testdatenset gemessen. Das Qualitätsmaß bestimmt ganz wesentlich die Richtung, in der die verschiedenen Hyperparameter eingestellt werden. Es muss daher dringend mit der sozialen Situation, in der das algorithmische Entscheidungssystem eingesetzt werden soll, in Einklang gebracht werden. Hier werden wesentliche ethische Entscheidungen getroffen. (KZ-AKT 202)
AES: Algorithmisches Entscheidungssystem
»algorithmische Entscheidungssystem«: Es besteht aus Daten, dem Verfahren zur Erstellung des statistischen Modells, allen Modellierungs- und Operationalisierungsentscheidungen, dem statistischen Modell selbst und dem Algorithmus, der mithilfe des statistischen Modells eine Entscheidung fällt. (KZ-AKT 232)
Kontrollforderungen
Transparenzforderungen
- Forderung nach Einsicht in die getroffenen Entscheidungen
Nachvollziehbarkeitsforderungen
- Mechanismen und Prozesse werden gefordert, mit denen unabhängige Experten die Resultate und das allgemeine Verhalten des Entscheidungssystem eigenständig untersuchen können.
Risikomatrix
- 5 Kategorien an technischer Regulation
Das vorgestellte Regulierungsmodell ersetzt den von Viktor Mayer-Schöneberger und Kenneth Cukier geforderten Algorithmen-TÜV, der zu sehr auf »den Algorithmus« fokussiert war. (KZ-AKT 245)
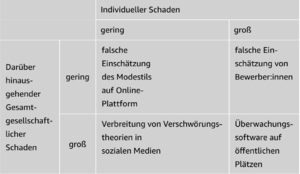
Beispiele für algorithmische Entscheidungssysteme, bei denen der individuelle Schaden und der darüber hinausgehende gesamtgesellschaftliche Schaden jeweils gering oder groß sind. (aus: KZ-AKT 236-7)
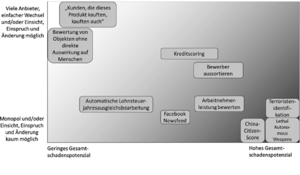
Risikomatrix zur Beurteilung der notwendigen Regulierung auf technischer Ebene mit einigen beispielhaft eingeordneten algorithmischen Entscheidungssystemen. (aus: KZ-AKT 239)
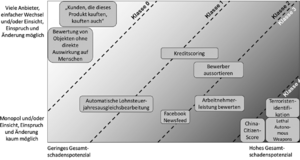
Die Risikomatrix wird in fünf Klassen unterteilt, mit jeweils eigenen Anforderungen an Transparenz und Nachvollziehbarkeit. (aus: KZ-AKT 242)
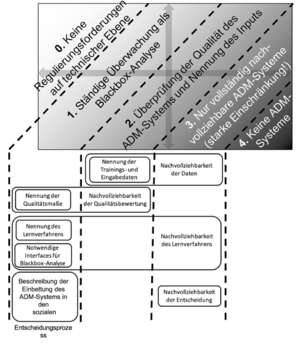
Zusammenfassung der Transparenz- und Nachvollziehbarkeitsforderungen in den fünf unterschiedlichen Klassen von algorithmischen Entscheidungssystemen. (aus: KZ-AKT 245)
Menschenbild dahinter
Der Mensch ist ein schlechter Entscheider
Annahme:
- Der Mensch ist ein schlechter Entscheider
- zu evaluieren: tatsächlich so schlecht?
- Qualitätsmaß
- Feststellen ob die gewünschte Veränderung tatsächlich eingetreten ist
Prognostizierbarkeit zukünftigen Verhaltens
Annahmen:
- eigenschaftsbasiertes Verhalten
- Operationalisierbarkeit und Beobachtung aller kausaler Parameter
- Transferierbarkeit (der Prognose von einer Gruppe auf einen Einzelnen)
Ich kenne allerdings kein Lehrbuch oder Handbuch, das diese drei Annahmen explizit nennt und verlangt, ihre Gültigkeit zu überprüfen, bevor das statistische Modell zur Vorhersage künftigen Verhaltens genutzt wird. (KZ-AKT 255)
Schwache & starke KI
Aber wenn es eine starke KI geben soll, kommen wir um eine »Master-Optimierungsfunktion«, mit der sie ihre Handlungen bewertet, nicht herum. (KZ-AKT 273)
Sowohl die notwendige Datenauswahl als auch die Operationalisierung von sozialen Konzepten ist aber – wie am Beispiel der MIT-Studie und vielen weiteren soziologischen Studien zu sehen – stark kulturell geprägt. (KZ-AKT 277-8)
Die Ausgangsbedingungen für eine starke KI sind also schlecht: Sie braucht eine Optimierungsfunktion, diese muss aber – wenn sie menschenzentriert sein soll – eine sinnvolle Auswahl an Daten bekommen und soziale Konzepte operationalisieren. Beides ist stark von kulturellen Perspektiven abhängig. (KZ-AKT 278)
Ich glaube, dass die Menge der möglichen Optimierungsfunktionen einer starken KI, die menschheitsverträglich sind, unendlich klein ist gegenüber der Menge möglicher Optimierungsfunktionen, die keine positiven Auswirkungen auf den Planeten, seine Flora und Fauna inklusive der Menschheit hätten. (KZ-AKT 279-280)
Interpretierbarkeit
https://ff06-2020.fastforwardlabs.com/









